El campo de la analítica predictiva es cada vez más prometedor para ayudar a los médicos a diagnosticar y tratar a los pacientes. Los modelos de aprendizaje automático pueden estar formados para encontrar patrones en los datos de los pacientes como por ejemplo ayudar al cuidado de la sepsis, diseñar tratamientos de quimioterapia más seguros y predecir el riesgo de que una paciente desarrolle cáncer de mama.
Por lo general, los conjuntos de datos de capacitación consisten en muchos sujetos enfermos y sanos, pero con relativamente pocos datos para cada sujeto. Los expertos deben entonces encontrar solo aquellos aspectos o ‘características’ en los conjuntos de datos que serán importantes para hacer predicciones.
“Cada vez es más fácil recopilar conjuntos de datos de series de tiempo largas. Pero hay médicos que necesitan aplicar sus conocimientos para etiquetar el conjunto de datos”
Esta ‘ingeniería de característica’ puede llegar a ser un proceso laborioso y costoso. Pero se está volviendo aún más difícil con el aumento de los sensores que se pueden llevar puestos. Así, por ejemplo, los investigadores pueden monitorear fácilmente la biometría de los pacientes durante largos periodos, rastreando los patrones de sueño, la forma de andar y la actividad de la voz. Después de una semana de monitoreo, los expertos pueden llegar a obtener varios miles de millones de muestras de datos para cada sujeto.
Modelo de características que predice trastornos en las cuerdas vocales
En un documento presentado en la conferencia ‘Machine Learning for Healthcare’ de esta semana, los investigadores del MIT demuestran un modelo que aprende automáticamente características que predicen los trastornos de las cuerdas vocales. Las características provienen de un conjunto de datos de alrededor de 100 sujetos. Cada uno con aproximadamente una semana de datos de monitoreo de voz y varios miles de millones de muestras. El conjunto de datos contiene señales de un pequeño sensor de acelerómetro montado en los cuellos de los sujetos.
En los experimentos, el modelo empleó características extraídas automáticamente de estos datos para clasificar, con alta precisión, a los pacientes con y sin nódulos en las cuerdas vocales. Estas son lesiones que se desarrollan en la laringe, a menudo por patrones de mal uso de la voz, como el canto o los gritos. Cabe señalar que el modelo llevó a cabo esta tarea sin un gran conjunto de datos etiquetados a mano.
El modelo empleó características extraídas automáticamente de estos datos para clasificar, con alta precisión, a los pacientes con y sin nódulos en las cuerdas vocales.
“Cada vez es más fácil recopilar conjuntos de datos de series de tiempo largas. Pero hay médicos que necesitan aplicar sus conocimientos para etiquetar el conjunto de datos”, dice el autor principal José Javier González Ortiz, estudiante de doctorado en el Laboratorio de Ciencias de la Computación e Inteligencia Artificial del MIT. “Queremos quitar esa parte manual para los expertos y descargar toda la ingeniería de características a un modelo de machine-learning”.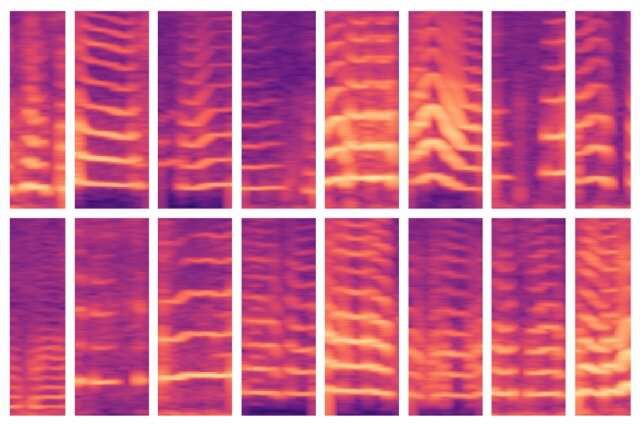
Imagen de los investigadores sobre trastornos en las cuerdas vocales
De esta manera, el modelo puede ser adaptado para aprender patrones de cualquier enfermedad. La capacidad de detectar los patrones de uso diario de la voz asociados con los nódulos de las cuerdas vocales es un paso importante en el desarrollo de métodos mejorados para prevenir, diagnosticar y tratar el trastorno, explican los investigadores.
Aprendizaje forzado de características
Durante años, los investigadores del MIT han trabajado con el Centro de Cirugía Laríngea y Rehabilitación de la Voz para desarrollar y analizar datos de un sensor para rastrear el uso de la voz del sujeto durante todas las horas de desvelo. El sensor es un acelerómetro con un nodo que se pega al cuello y está conectado a un Smartphone. Mientras la persona habla, el Smartphone recoge datos de los desplazamientos en el acelerómetro.
En su trabajo, los investigadores recolectaron el valor de una semana de esos datos de 104 sujetos, la mitad fueron diagnosticados con nódulos en las cuerdas vocales. Por su parte, los investigadores forzaron al modelo a aprender características sin la información del sujeto.
Así, el modelo debe asegurar que el espectrograma descomprimido se asemeja mucho a la entrada original del espectrograma. Al hacerlo, se ve obligado a aprender la representación comprimida de cada entrada de segmento de espectrograma sobre la totalidad de los datos de series de tiempo de cada sujeto. Las representaciones comprimidas son las características que ayudan a entrenar modelos de aprendizaje de máquinas para hacer predicciones.
Mapeo de características normales y anormales
En la formación, el modelo aprende a asignar esas características a ‘pacientes’ o ‘controles’. Los pacientes tendrán más patrones de voz que los controles. Si el sujeto tiene segmentos de voz mayormente anormales, se clasifican como ‘pacientes’; si tienen segmentos de voz mayormente normales, adquieren el estatus de ‘controles’.
Asimismo, los investigadores quieren monitorear cómo varios tratamientos, como la cirugía y la terapia vocal, impactan en el comportamiento vocal. Si los comportamientos de los pacientes se mueven de forma anormal a lo habitual con el tiempo, lo más probable es que mejoren. También esperan usar una técnica similar en los datos de electrocardiograma, que se usa para rastrear las funciones musculares del corazón.











 Si (
Si ( No(
No(
: 'Llegaremos a los 22 millones de hogares antes de final de año'")












