En los últimos 10 años, el programa de traducción de Google ha crecido desde traducir unas pocas lenguas a 103 en total, traduciendo la asombrosa cifra de 140 mil millones de palabras cada día.
Para mantener esta maquinaria, Google ha creado diversos sistemas que permitan la traducción entre dos lenguas cualquiera, lo que implica un elevado coste computacional.
Con la mira puesta en las redes neuronales, Google destaca su apuesta por mejorar la calidad de traducción, pero “hacerlo significaría repensar la tecnología que está detrás de Google Translate”.
En los últimos 10 años, el programa de traducción de Google ha crecido desde traducir unas pocas lenguas a 103 en total, traduciendo la asombrosa cifra de 140 mil millones de palabras cada día
En el mes de septiembre, Google anunció un cambio de sistema que se denomina Google Neural Machine Translation (GNMT), una tecnología de aprendizaje de extremo a extremo que retiene millones de ejemplos y proporciona mejoras significativas en la calidad de la traducción.
Hasta el mes de septiembre de 2016, Google Translate empleaba una traducción basada en frases, la misma que realizaría cualquier persona al utilizar un diccionario tradicional. Para salir del paso era suficiente, pero los resultados eran bastante crudos y no realizaba una comprensión de las estructuras lingüísticas, lo que resulta en una traducción no correcta.
Este enfoque está limitado también por el alcance del vocabulario disponible. La traducción basada en frases no tiene la opción de realizar conjeturas basadas en palabras que no reconoce y no puede aprender de nuevos aportes.
Todo esto se terminó en septiembre, con la incorporación de GNMT a Google Translate. En resumen, la herramienta de traducción de Google es más inteligente. Ha desarrollado la habilidad de aprender de las personas que lo utilizan. Ha aprendido a realizar conjeturas educadas sobre el contenido, el tono y el significado de frases basadas en el contexto de otras palabras y frases que la rodean.
Google Translate se ha inventado su propio lenguaje para que la traducción sea más eficaz.
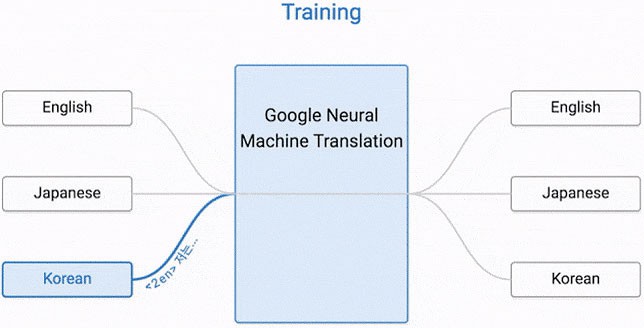
Traducción zero-shot
Para entender bien lo que está pasando, hay que entender la capacidad de la traducción zero-shot.
En el artículo publicado por Mike Schuster, Nikhil Thorat y Melvin Johnson en el blog oficial, se explica.“Digamos que entrenamos un sistema multilingüe con ejemplos japonés-inglés y coreano-inglés. Nuestro sistema multilingüe, con el mismo tamaño que un único sistema GNMT, comparte sus parámetros para traducir entre estas cuatro parejas (cada ejemplo va en ambas direcciones) de idiomas. Este intercambio permite al sistema transferir el “conocimiento de la traducción” de una pareja de idiomas a los otros. Este aprendizaje de transferencia y la necesidad de traducir entre múltiples lenguajes obligan al sistema a utilizar mejor su poder de modelado.
Esto forzó a que se preguntaran si el sistema era capaz de traducir entre un par de idiomas que el sistema no había visto anteriormente. Por ejemplo, traducir entre coreano y japonés en el caso en el cual no se mostrarán ejemplos coreanos-japoneses al sistema. Para nuestra sorpresa, la respuesta fue sí. Puede generar traducciones coreano-japonesas razonables, aunque nunca se le haya enseñado a hacerlo.”
El GMNT es capaz de aprender a traducir entre dos lenguas sin que se la haya enseñado de manera explícita
En esto podemos ver una asombrosa ventaja de la nueva máquina neuronal de Google sobre el antiguo enfoque basado en frases. El GMNT es capaz de aprender a traducir entre dos lenguas sin que se la haya enseñado de manera explícita. Esto sería impensable en un modelo basado en frases, donde la traducción depende íntegramente de un diccionario explícito para asignar palabras y frases entre cada pareja de idiomas traducidos.
Y esto llevo a los ingenieros de Google a descubrir lo asombroso de la creación: el éxito de la traducción zero-shot plantea una pregunta importante, ¿está el sistema aprendiendo una representación común en la que las oraciones con el mismo significado están representadas de manera similar independientemente del idioma, es decir, interlingua?
“Utilizando una representación tridimensional de los datos internos de la red, pudimos echar un vistazo al sistema a la vez que traducía un conjunto de frases entre todas las parejas posibles formadas por los idiomas japonés, coreano e inglés”.
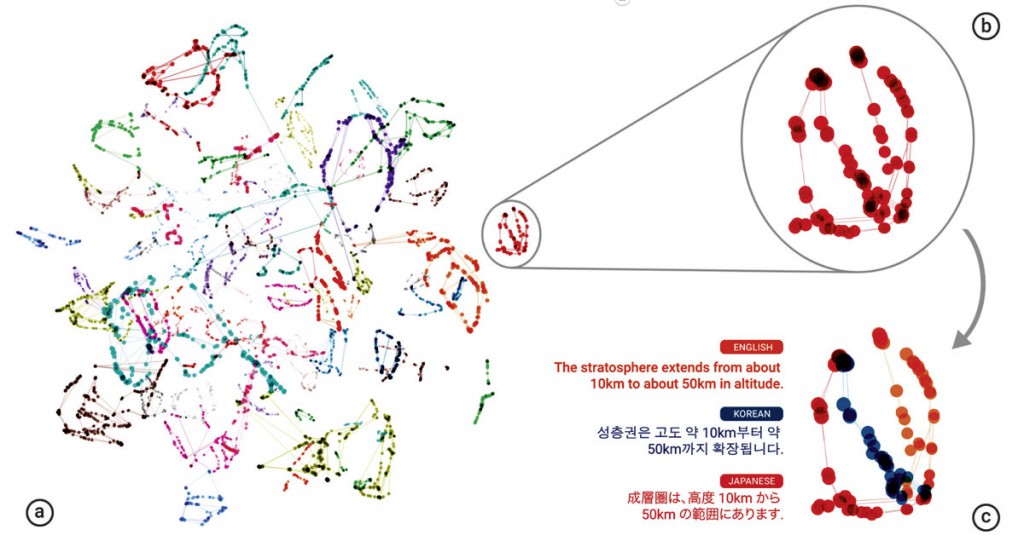
Dentro de un solo grupo, vemos una oración con el mismo significado, pero de tres idiomas diferentes. Esto significa que la red debe codificar algo sobre la semántica de la frase en lugar de simplemente memorizar las traducciones de frase en frase. Interpretamos esto como un signo de existencia de una interlingua en la red”.
Ejemplificando el asunto. Un niño tarda años en aprender su primer idioma, sin embargo, tan solo cuesta un poco aprender un segundo lenguaje. Entonces, volviendo al tema de la Inteligencia Artificial, cuando ha aprendido un idioma, queremos que haga lo mismo que un niño. Queremos que le sea sencillo aprender el segundo.
Aquí es donde entran en juego las redes neuronales artificiales. Están compuestos de tres partes: inputs, neuronas y outputs. Las neuronas son donde ocurre la magia, modeladas en los cerebros. Son una mancha de neuronas que pueden conectarse entre sí o cortar enlaces para que puedan unirse un poco del cerebro a otro y dejar que una señal vaya de un lugar a otro. Esto es lo que une los inputs a los outputs. Entonces, siguiendo la teoría del conocimiento clásico, cuando algo bueno ocurre, el cerebro lo recuerda fortaleciendo el nexo existente entre las neuronas. Pero al igual que ocurre con un bebé, esto comienza de manera muy aleatoria por lo que lo único que sale son balbuceos de bebe, pero no queremos eso, tenemos que enseñarle cómo llegar de “perro” a “chien” (perro en francés), no de “perro” a “guauguau”.
Dentro de un solo grupo, vemos una oración con el mismo significado, pero de tres idiomas diferentes. Esto significa que la red debe codificar algo sobre la semántica de la frase en lugar de simplemente memorizar las traducciones de frase en frase
Entonces, al enseñarle la red neuronal artificial, le das un input, y si el output es incorrecto, le das un golpe en la nariz, entonces las neuronas recuerdan que “lo que acabamos de hacer está mal, no lo hagas de nuevo” disminuyendo el valor que tienen los nexos entre las neuronas que lo llevaron a una respuesta equivocada. Mientras que, si lo hace bien, darle unas palmaditas en la espalda y hará lo contrario, aumentará los nЬmeros y esto significa que será más probable que la próxima vez tome ese camino. Es decir, que, con el tiempo, el input “perro” irá unido al output “chien”.
Es decir, la red neuronal artificial funciona en ambas direcciones, de tal manera que al darle un output nos puede dar un input siguiendo el camino de las neuronas en la dirección opuesta. Es decir, que si le enseñamos que “perro” significa “chien”, también sabrá que “chien” significa “perro”. Esto significa también, que podemos enseñarle que “dog” significa “perro” en inglés. O sea que cuando se lo enselemos, la manera más rápida para ir de “dog” a “perro” es seguir el camino de “chien” a “perro”. Es decir, que con el tiempo tirará de las neuronas que unen “chien” y “perro” más cerca de “dog”, por lo que también unirá “dog” y “chien”.

Esta triple conexión que hay entre “perro”, “dog” y “chien” es el lenguaje que la Inteligencia Artificial de Google ha creado por sí mismo.
Es decir, que, siguiendo el ejemplo del niño imaginario que comentábamos antes, lo que la IA de Google hace es sencillo. El niño lo que hace al aprender un idioma no es un diccionario del idioma, sino que oyen las palabras y las unen a la idea que representa dicha palabra. Motivo por el cual las citas, generalmente, de películas son erróneas, recordamos lo que la cita significaba, pero no las palabras exactas.
De este modo, cuando el niño aprende un segundo idioma, escuchan “chien” como francés, pero lo unen a la idea de perro. De tal modo que cuando escuchan “dog”, lo oyen en inglés, pero también lo asocian a la idea de perro. Es decir, que el niño sólo debe aprender sobre la idea de perro una vez, pero puede vincular esa idea a muchos idiomas o sinónimos de perro. Y esto es lo que hace la IA de Google.
En lugar de pensar si “perro” es lo mismo que “chein” y “chein” es lo mismo que “dog” y por tanto, “perro” es lo mismo que “dog”, lo que hace es pensar que “perro” es igual a “X”, que es lo mismo que “chien”, que es lo mismo que “dog” que es lo mismo que “X” (X es igual a la idea de perro”). Es resumen, puede convertir “X” en el idioma que sea.
En conclusión, gracias a este desarrollo de la IA de Google, las traducciones realizadas con Google Translate son mucho mejores que las que se realizaban hace algunos meses y con una arquitectura productiva mucho más sencilla y veloz












 Si (
Si ( No(
No(
: 'Llegaremos a los 22 millones de hogares antes de final de año'")












