Pese a errar en octavos contra el PSG y en cuartos contra el Chelsea, el big data tenía muy claro que el Real Madrid no ganaría al City en su estadio. La tecnología, que se usa en diferentes competiciones, solo le daba una posibilidad de victoria del 15% a la entidad madridista para el partido de ida disputado en el Etihad Stadium. El 4-3 a favor del equipo de Guardiola dio la razón a la inteligencia artificial de Google que para el partido de vuelta en el Bernabéu sólo daba un 29% de opciones a la remontada blanca y señalaba que el City era el favorito para salir con la victoria con un 46%.
Es más, las probabilidades de remontada del Real Madrid bajaron hasta el 1% a falta de un par de minutos, según se pudo ver sobreimpresionado en la retransmisión. Y hubiera acertado de no haber sido porque un Rodrygo, en estado de trance, marcó dos goles para mandar el partido a la prórroga. El resto es épica, magia o lo que cada uno quiera creer o llamar. ¿Se volvió a equivocar el big data en la Champions League? ¿Miente el big data?
¿Dónde está el error?
“El big data no miente, solo es capaz de ofrecer respuestas sobre aquellas situaciones que se han producido previamente de manera más común”
“Los pronósticos se basan en modelos matemáticos que calculan probabilidades de que un evento ocurra, por lo que aquellas situaciones que son poco comunes, que no han ocurrido aún y son poco probables son muy difíciles de predecir”, apunta Moisés Martínez responsable de IA en Paradigma Digital. “El big data no miente, solo es capaz de ofrecer respuestas sobre aquellas situaciones que se han producido previamente de manera más común. Para predecir un resultado necesitamos construir un modelo matemático, normalmente mediante aprendizaje automático, que extrae patrones o situaciones que aparecen de manera común en los datos, si un patrón no aparece en muchas ocasiones se considerará que es poco probable”, añade Martínez.
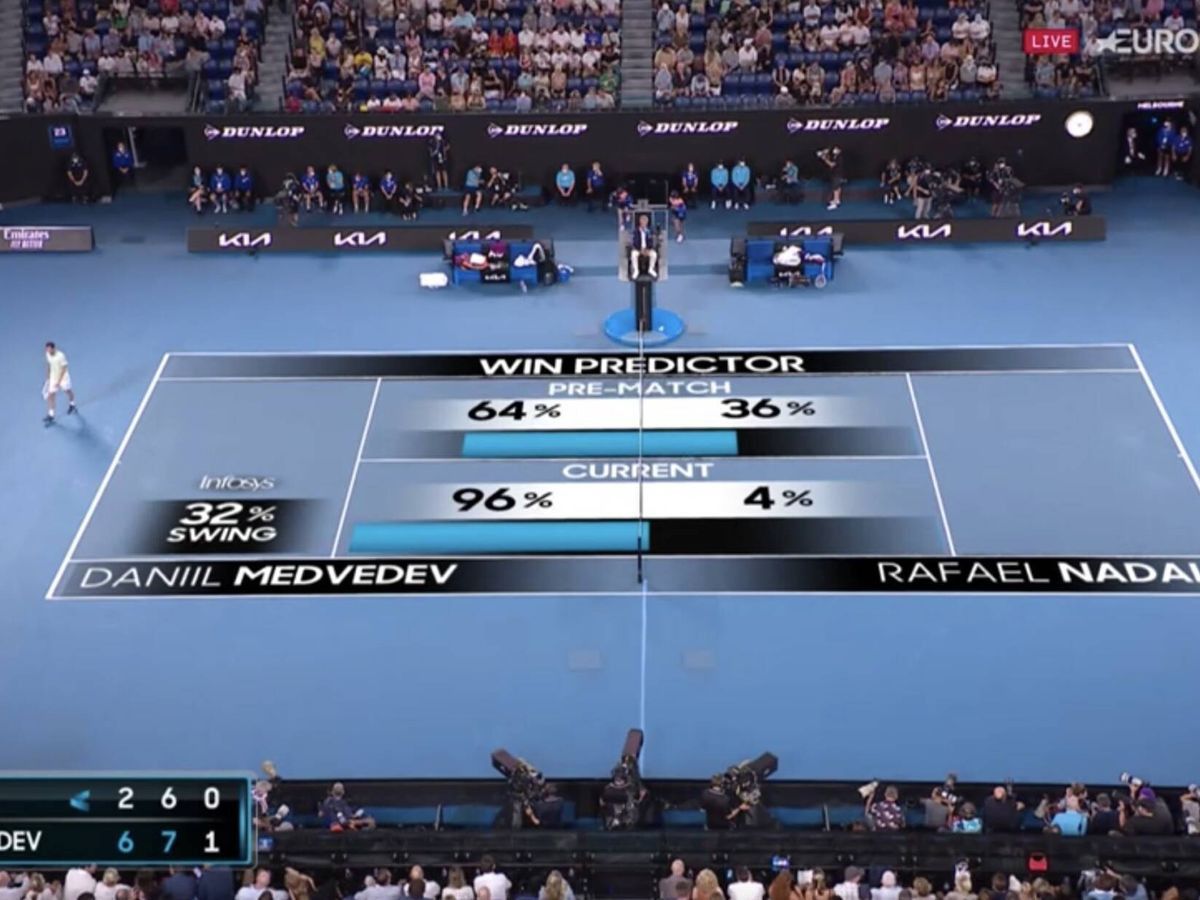
Es lo que ocurrió el pasado Open de Australia en el que, con dos sets en contra, Rafa Nadal fue capaz de remontar el partido a Medvedev para convertirse en el único tenista masculino con 21 Grand Slam. El big data solo daba al balear un 4% de opciones de llevarse el trofeo.
“La materia prima son los datos y es fundamental que sean de calidad y permitan describir correctamente el problema que se esté estudiando”
“La fiabilidad de los pronósticos está íntimamente ligada a la materia prima con la que se trabaja y a la matemática que se les aplica. En este caso, la materia prima son los datos y es fundamental que sean de calidad y permitan describir correctamente el problema que se esté estudiando. Cuantas más fuentes de datos relevantes se tengan para trabajar y mayor sea el historial disponible, mejor se podrá describir el contexto en el que se desarrolla el problema que se quiere resolver y, por tanto, más fácil será para el sistema de IA conocer y aprender”, explica Gaizka San Vicente, CTO de Olocip.
Sin embargo, el experto advierte de que toda esa materia prima por sí sola no es suficiente y que es fundamental elegir bien los tipos de algoritmos matemáticos que se van a encargar de responder a las preguntas que se hagan al sistema y entrenar correctamente los modelos de inteligencia artificial que las integran. “En consecuencia, es necesario tener una buena materia prima y una matemática adecuada para que el sistema inteligente ofrezca pronósticos fidedignos y cercanos a la realidad”, señala San Vicente.
El entrenador Boza Maljkovic solía repetir la conocida frase de que las estadísticas son como los bikinis, muestran cosas muy sugerentes, pero ocultan las cosas importantes. Ya que en las estadísticas tan importante es el volumen de datos como su calidad y en el caso de los pronósticos hay que sumarle la complejidad del algoritmo matemático con el que se hace el modelo predictivo, de ahí que haya tantas variaciones en los pronósticos de las diferentes compañías que proporcionan estadísticas y en las casas de apuestas.
“Hay enfoques muy simples que únicamente se fijan en el marcador y analizan lo que ha ocurrido en el pasado en una situación similar mientras que otros generan modelos complejos que estudian cada desplazamiento, cada jugada, cada tiro… y con la interconexión de todas las variables hacen un modelo que “entiende” lo que está ocurriendo y puede predecir la probabilidad de que ocurra determinado suceso”, apunta San Vicente.
“La imprevisibilidad depende de la cantidad de información que tengamos para predecir el resultado”
Ante situaciones excepcionales, el reto pasa por entrenar a la inteligencia artificial para que aprenda a usar los datos asociados a esas casuísticas improbables para poder predecirlas en el futuro. Como advierte Martínez, “la imprevisibilidad depende de la cantidad de información que tengamos para predecir el resultado, no podemos predecir si va a haber alguien en una habitación si solo miramos a través del agujero de la cerradura, y sí si miramos a través de un conjunto de cámaras que nos permiten observar la habitación de manera completa”.
Big Data, una prioridad en la industria del deporte
Leer más
¿Cuántos datos son necesarios analizar?
Olocip trabaja con una media de 10.000 datos por partido. En cambio, el Proyecto FiveThirtyEight trabaja con 50.000 simulaciones sobre la temporada con un modelo de algoritmo que no se basa en el clásico modelo Elo de victorias y derrotas, sino que tiene en cuenta las proyecciones de los jugadores de la NBA que estiman el rendimiento futuro de cada jugador en función de la trayectoria de jugadores similares de la NBA. Estos se combinan con tablas de profundidad actualizadas (seguimiento de lesiones, intercambios y otras transacciones de jugadores) para generar estimaciones de talento para cada equipo. La calificación de fuerza completa de un equipo asume que todos sus jugadores clave estarán en la alineación de los partidos.
Pese a ese volumen de datos, la compañía americana en diciembre de 2020 daba un 10% de opciones a los Bucks para alzarse con el anillo de campeones de la NBA 20/21. Un porcentaje que subió al 14% en enero, unas semanas antes del All Star de mitad de temporada y que, sin embargo, volvió a bajar al 9% al comenzar los playoffs. Al final, el equipo de Giannis Antetokounmpo venció 4-2 a los Suns para llevarse a Milwaukee un título 50 años después de que Kareem Abdul-Jabbar (por entonces Lew Alcindor) lo ganara para el equipo de los ciervos. Curiosamente, los Suns solo tenían un 3% de opciones de alzarse con el título al empezar los playoffs según la misma web, por lo que ahí sí acertó.

Pero para las finales de este año las predicciones no han ido mucho mejor. Al inicio de la temporada NBA el pasado mes de noviembre daban un 0,4% de probabilidades de que los Warriors de Curry se alzaran con el anillo (y un 1% de llegar a la final), mientras que los Dallas de Doncic arrojaban un 2% de opciones y un 6% respectivamente. Uno de los dos equipos jugará las finales de este año contra el ganador de Heat y Celtics, éste último con un 43% de probabilidades de ganar el anillo, según las predicciones del 16 de mayo (frente al 35% de Dallas).
A la espera de ver qué sucede este año, la pregunta que surge es que si con 50.000 datos tampoco es probable acertar ¿cuántos datos habría que analizar y hasta dónde habría que profundizar para conseguir un pronóstico infalible?
“Probablemente nunca vayamos a conseguir un pronóstico infalible debido a la complejidad del resultado a predecir”
“Es muy difícil responder a esta pregunta, ya que probablemente nunca vayamos a conseguir un pronóstico infalible debido a la complejidad del resultado a predecir. Esto es debido a que cuanto mayor número de variables, es decir número de información que incluyamos en los datos con el objetivo de aumentar la precisión de la predicción, mayor cantidad de ejemplos necesitaremos debido a que habremos aumentado el número de posibles casos debido al aumento de las variables”, argumenta Martínez.
“En principio, cuantas más fuentes de datos se tengan mejor. Imagínese todo lo que se podría estudiar si se tuviera información como el nivel de sudoración, el grado de deshidratación, los esfuerzos musculares realizados en cada paso, estudios de microbioma...”, enumera San Vicente.
Lo cierto es que con la digitalización de estadios, con sensores cada vez más pequeños y en todo tipo de prendas y tejidos, y la aplicación del big data a la medicina preventiva para mimar la salud de los deportistas el número de datos que se analizan no deja de crecer exponencialmente. La americana Sports Data Lab está usando un pequeño sensor para analizar en tiempo real el ritmo cardiaco de los deportistas, mientras que la española Humanox ha lanzado sus espinilleras inteligentes HUOX 50, capaces de procesar más de 50.000 datos por entrenamiento o partido, ofreciendo más de 40 métricas dirigidas no solo a mejorar el rendimiento deportivo, sino a cuidar de la salud del deportista.
Tecnología y deporte, dos mundos cada vez más unidos
Leer más
Cómo medir lo intangible
Claro que en ejemplos como el de Rafa Nadal y su inquebrantable fe o el del Real Madrid y los “90 minuti en el Bernabeu son molto longos” de Juanito, hay datos que son difíciles de medir para meter en el algoritmo de la ecuación. ¿Cómo se pueden medir en datos las creencias religiosas de Rodrygo? ¿Hasta qué punto influyen sus creencias en el resto de los compañeros? ¿Hasta dónde tendría que llegar a analizar el big data el estado de ánimo de un jugador, sus compañeros, su familia, resto de empleados del club, la afición…? Por ejemplo, Google sí tuvo en cuenta para su algoritmo de inteligencia artificial cuando anticipó un 37% de probabilidades de que el Real Madrid remontaría ante los Neymar, Messi y Mbappé por aquello de la magia del Bernabéu, aunque no explicó cómo midió esa variable.
“Las predicciones serán mejores cuanto mejor sea la calidad y no solo la cantidad de la información que utilizamos para generarlas”
“Es muy difícil describir de manera matemática cómo pueden influir las creencias religiosas o el ímpetu de la afición al empujar con sus ánimos a un equipo o a un jugador a remontar una situación en contra, sí que tienen algún tipo de influencia. Pero, lo que sí es seguro, es que las predicciones serán mejores cuanto mejor sea la calidad y no solo la cantidad de la información que utilizamos para generarlas, por lo que habrá que aumenta el tipo, el número y la calidad de los datos que se utilizan, e incluso así seguiremos fallando en algunos casos poco probables que se hayan dado pocas veces”, apunta Moisés Martínez.
“Hay información que se puede obtener de manera indirecta. A veces, los datos que se recogen son redundantes y por tanto no aportan nada nuevo al modelo de inteligencia artificial. En otras ocasiones, la influencia que puede tener determinado aspecto sobre el rendimiento final es tan pequeña que no interesa incluirlo en el modelo. En este tipo de sistemas, hay que ver qué datos se pueden recoger de manera fiable y cómo de accesibles están para ponerlos en la balanza y ver si compensa tenerlos en cuenta”, reseña San Vicente.

Ambos expertos coinciden en la necesidad de disponer del mayor número de datos posibles. Al fin y al cabo, es lo que hace Google para conocernos. Como señala Stephens-Davidowitz en su libro ‘Todo el mundo miente: lo que internet y el big data pueden decirnos sobre nosotros mismos’, al final de un día promedio a principios del siglo XXI, los seres humanos que buscan en Internet acumularán ocho billones de gigabytes de datos. Esta asombrosa cantidad de información, sin precedentes en la historia, puede decirnos mucho sobre quiénes somos, los miedos, deseos y comportamientos que nos impulsan y las decisiones conscientes e inconscientes que tomamos.
Los noventa minutos de un partido de fútbol o las tres o cuatro horas de uno de tenis dan lugar a la recopilación de infinidad de datos.
“Cuando hablamos de tareas complejas con cientos de miles de variables para predecir el resultado de un partido y en fracciones de tiempo tan largas como 90 minutos, en cualquier instante se puede producir un evento inesperado”
“Lo mejor es que los datos siempre sean de buena calidad, y a ser posible validados por humanos, estén balanceados y sean suficientemente representativos con respecto a todas las posibles situaciones que se puedan dar. Pero cuando hablamos de tareas complejas con cientos de miles de variables para predecir el resultado de un partido y en fracciones de tiempo tan largas como 90 minutos, en cualquier instante se puede producir un evento inesperado. Como dijo el célebre físico teórico Stephen Hawking “Dios no solo juega a los dados con el universo: a veces los arroja donde no podemos verlos” y esto nos lleva a la conclusión que existen variables y situaciones que no hemos considerado o visto y por tanto no están reflejadas en nuestros datos”, comenta Martínez.
Para San Vicente, lo ideal es que haya una amplia variedad de fuentes de datos para poder hacer un estudio inicial de cuáles de ellas son interesantes. A veces, determinadas variables se descartan porque no son relevantes, aportan poco o son redundantes. En otras ocasiones, sin embargo, el problema está en que se disponen de manera incompleta. Por ejemplo, en un sistema orientado al estudio táctico, si solo tenemos las posiciones de los jugadores de un equipo de fútbol, pero no disponemos de las del rival, no podemos analizar lo que ha ocurrido en el partido con suficiente nivel de detalle.
“Hay que tener en cuenta que ante un mismo problema se pueden emplear diferentes estrategias en función de las necesidades y requisitos que se tengan”
“Por otro lado, hay que tener en cuenta que ante un mismo problema se pueden emplear diferentes estrategias en función de las necesidades y requisitos que se tengan. Por ejemplo, un sistema que tiene que responder en tiempo real tiene una serie de limitaciones por el simple hecho de que, a partir de un límite, no puede procesar más información y hacer los cálculos correspondientes y, por tanto, el límite viene dado por la capacidad de cómputo”, explica San Vicente.
La variedad de datos y fórmulas matemáticas para entrenar a la inteligencia artificial es lo que hace que surjan tantas diferencias en los pronósticos, sobre todo en lo que se refiere a las casas de apuestas que también tienen que hacer frente a la imprevisibilidad. El ejemplo más sonado es el del Leicester City cuando ganó la Premier League en la temporada 2015-2016. Pocos creían en la hazaña de los foxes, salvo un creyente aficionado que apostó 50 libras al inicio de la temporada a que su equipo ganaría el título en una rocambolesca combinación que la casa de apuestas Ladbrokes pagaba a 5.000/1. Tampoco era para tanto si tenemos en cuenta que el Leicester no había ganado el título en sus 132 años de historia.
Sin embargo, a medida que la temporada avanzó y que parecía que el combinado de Claudio Ranieri tenía opciones al irse distanciando del Arsenal (al que acabó sacando diez puntos), Ladbrokes llegó a un acuerdo con el aficionado visionario para pagarle 76.000 libras esterlinas a cambio de retirar una apuesta que, en caso de victoria final, valdría hasta tres veces más.
La inteligencia artificial ayudará a encontrar al próximo Messi o Ronaldo
Leer más
Acertar siempre es difícil
El caso del Leicester o de los Bucks demuestran que lo improbable puede ocurrir tanto en el largo plazo como en el corto (los ejemplos del Real Madrid y Nadal).
“Si son acciones que no se han dado antes nunca o solo de manera marginal es normal que erremos ya que normalmente la información que usamos para predecir es muy pequeña y puede que no incluya aquella información que nos permite predecir una acción o un evento”, explica Martínez.
En 2016 predijo, la IA acertó que el Real Madrid ganaría el título y que Barcelona, Atlético de Madrid y Sevilla se clasificarían para la Champions
Claro, que lo fácil es quedarse siempre con la anécdota del error, cuando la inteligencia artificial y el big data han acertado en numerosas ocasiones. Microsoft, que trabaja con LaLiga, suele anunciar los pronósticos de Bing para cada temporada. En 2016 predijo, y acertó, que el Real Madrid ganaría el título y que Barcelona, Atlético de Madrid y Sevilla se clasificarían para la Champions. Aunque la temporada siguiente falló con sus predicciones al prever el doblete de un equipo merengue que acabó tercero.
Más reciente aún, un análisis de expertos de Opta, Squawka y Google sobre los pronósticos de la Champions 2019/20 señalaba al Real Madrid como campeón, tras deshacerse del Manchester City en octavos de final, del Chelsea en cuartos, del Barcelona en semifinales y al imponerse al Bayern de Múnich en la gran final de Estambul, gracias a un gol de Luka Jovic. Acertaron a medias, ya que la final se trasladó por el Covid-19 a Lisboa y a un inusual mes de agosto, y allí el conjunto bávaro de Klopp se llevó su sexta orejona gracias a un solitario gol de Coman.

En la pasada Eurocopa 2020, también retrasada a 2021 por la pandemia, desde Goldman Sachs analizaron una base de datos de más de 6.000 partidos desde 1980 para hacer sus predicciones bajo un modelo matemático que tenía en cuenta factores como los goles marcados por cada selección, la fortaleza del conjunto (a partir del World Football Elo Ratings), los goles marcados y encajados en los últimos encuentros, la ventaja de jugar en casa o el “efecto torneo”, por el que hay selecciones que tienden a brillar en campeonatos mundiales respecto a su rating.
Según el cóctel de datos para Goldman Sachs, el campeón de la Euro2020 sería Bélgica, por primera vez en su historia, tras ganar ajustadamente en la final a Portugal. Ambas selecciones llegarían a la final Wembley tras eliminar a Italia y España en semifinales. Curiosamente estas dos selecciones fueron las que protagonizaron una de las semifinales, la otra Dinamarca contra Inglaterra, que acabaría sucumbiendo ante la escuadra azzurra por penaltis.
“Habría que analizar cómo se han hecho los modelos predictivos y qué variables tienen en cuenta”
“En estos casos también habría que analizar cómo se han hecho los modelos predictivos y qué variables tienen en cuenta. Ya que otro tema importante a la hora de desarrollar modelos de inteligencia artificial es decidir si se da prioridad a que el sistema acierte los resultados en determinadas situaciones (por ejemplo, cuando juegan determinados equipos) o si, por el contrario, se prefiere que sea más generalista y funcione correctamente en cualquier situación. Este tipo de decisiones condicionan la precisión de los modelos en determinados casos y requieren una interpretación más detallada”, apunta el CTO de Olocip.
Fan engagement, el verdadero Balón de Oro
Leer más
Predecir la magia
Como hemos visto, el número de datos y variables tiende a infinito. Y si añadimos a la combinación datos y etiquetas intangibles como la magia, el misticismo del estadio, el tesón del jugador… que son difícilmente representables en unos y ceros, la ecuación se complica. Por lo que la clave seguirá pasando por medir y analizar el mayor número de datos posibles de cosas que hoy no se miden.
“Realmente no monitorizamos el rendimiento deportivo de los jugadores de manera precisa, analizando su estado anímico y físico en tiempo real de manera completa”
“La magia y la fe no son variables tangibles que podamos utilizar, pero si hay muchas variables tangibles que actualmente no tenemos en cuenta. Realmente no monitorizamos el rendimiento deportivo de los jugadores de manera precisa, analizando su estado anímico y físico en tiempo real de manera completa, por lo que nos perdemos muchísima información que nos podría permitir generar mejores predicciones si fuéramos capaces de extraer, almacenar y analizar esa información”, comenta el responsable de inteligencia artificial de Paradigma Digital.
“A veces, hay conceptos que directamente no se pueden medir pero que indirectamente sí se pueden recoger. El que una persona tome una decisión más o menos acertada en un determinado momento puede estar condicionada por cómo ha dormido, el nivel de concentración, el cansancio acumulado o la hora a la que se produce el encuentro. Este tipo de datos, sumados al historial del deportista o equipo, pueden ayudar a predecir la probabilidad de que ocurra algo que aparentemente es sorprendente o “imposible”. De hecho, la capacidad de realizar esos eventos tan llamativos también se ve reflejada en el historial de datos y, por tanto, los modelos de inteligencia artificial pueden aprender de ellos”, opina San Vicente.

El deporte es emoción, sacrificio, fe… cosas que la inteligencia artificial igual no llega a entender aún como un humano
Igual llegar a entender el razonamiento matemático y la lógica detrás de la inteligencia artificial acabarían por eliminar ese halo de magia e ilusión por la remontada, por esa canasta ganadora sacada de la chistera o por ese pase imposible que acaba en touchdown. Al fin y al cabo, el deporte es emoción, sacrificio, fe… cosas que la inteligencia artificial igual no llega a entender aún como un humano.
Pero no nos olvidemos que al final los datos, también hay que entenderlos y comprender la idea que está detrás de la probabilidad, ya que lo que puede parecernos una mentira, en realidad refleja una verdad. “Cuando se indica que un determinado equipo tiene un 1% de probabilidad de ganar la contienda significa que, en esa situación, si se jugaran 100 partidos, en uno de esos cien ganaría”, advierte San Vicente.
Así que la próxima vez, cuando todo parezca perdido por los pronósticos del big data y la inteligencia artificial no se desanime ni abandone el estadio ni deje que decaiga el fan engagement. Puede que ese sea precisamente el partido que no volverá a ver hasta dentro de 99 ocasiones.
Fotos: Depositphotos















 Si (
Si ( No(
No(
: 'Llegaremos a los 22 millones de hogares antes de final de año'")












